Automatización del Estudio de Estado del Arte con Python e Inteligencia Artificial
Autor: Francisco Prats Quílez
Introducción
Este artículo presenta un enfoque innovador para la automatización del estudio de estado del arte en una tecnología específica, combinando la potencia de los modelos de lenguaje natural (LLMs) y las APIs disponibles. A través de una serie de pasos estructurados, se busca no solo simplificar la recopilación y análisis de datos relevantes, sino también mejorar la precisión y la eficiencia en la organización de la información obtenida. Desde la definición del alcance del estudio hasta la generación de un informe consolidado, cada etapa está diseñada para aprovechar al máximo las capacidades de la IA, reduciendo significativamente el esfuerzo humano requerido y minimizando el margen de error.
Objetivo
Automatizar el proceso de estudio de estado del arte en una tecnología específica mediante Python e inteligencia artificial, haciendo uso de modelos de lenguaje (LLMs) y APIs para extraer, analizar y organizar información relevante en un flujo eficiente.
Paso a Paso:
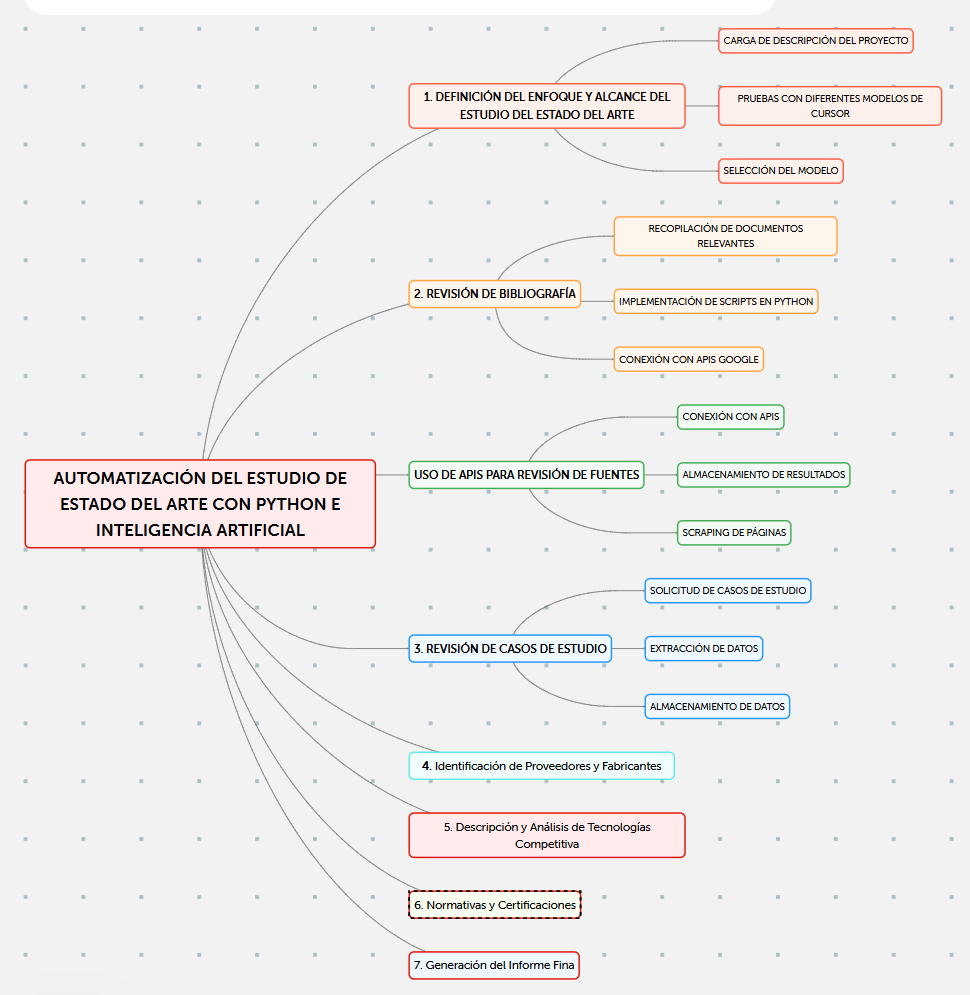
1. Definición del Enfoque y Alcance del Estudio del Estado del Arte
- Descripción:El primer paso consiste en definir el alcance del estudio de estado del arte a partir de una descripción inicial del proyecto. Utilizaremos modelos de lenguaje natural (LLMs) disponibles en Cursor para obtener esta definición.
- Carga de Descripción del Proyecto: La descripción del proyecto se envía a diversos modelos de lenguaje en Cursor para determinar su capacidad de respuesta.
- Pruebas con Diferentes Modelos de Cursor: Se realizan pruebas con diferentes modelos de lenguaje en Cursor, evaluando:
- Precisión y coherencia en la generación de contenido.
- Capacidad del modelo para delimitar áreas de investigación y tecnologías clave.
- Selección del Modelo: Se selecciona el modelo que haya demostrado mayor relevancia en la definición de alcance, enfoque y contexto técnico de las tecnologías involucradas en el proyecto.
- Resultado Esperado: Una estructura preliminar del estudio de estado del arte, con enfoque y alcance claramente definidos.
2. Revisión de Bibliografía
- Descripción: La revisión bibliográfica se enfoca en recopilar artículos académicos, patentes y otros documentos relevantes. Para esta fase, se implementarán scripts en Python para conectarse con APIs (como Google Patents y Google Scholar) y recopilar datos automáticamente.
- Implementación Técnica. Uso de APIs para Revisión de Fuentes:
- Conexión con la API de Google Patents para obtener patentes relevantes.
- Utilización de Google Scholar o alternativas (como Semantic Scholar) para artículos académicos.
- Almacenamiento de Resultados:Los datos se guardan en archivos .txt para mantener un repositorio de referencia inicial.
- Se incluye el uso de bibliotecas como requests y beautifulsoup4 para hacer scraping de páginas en caso de ausencia de APIs.
- Resultado Esperado: Un conjunto de archivos .txt que contienen referencias de artículos, patentes, y otros documentos de interés, organizados por relevancia y fecha.
3. Revisión de Casos de Estudio
- Descripción:En esta fase, el objetivo es identificar casos de estudio relevantes. Se solicita al modelo LLM que sugiera enlaces y luego se realiza scraping para obtener el contenido completo.
- Implementación Técnica. Solicitud de Casos de Estudio al LLM:
- El modelo sugiere enlaces de artículos, videos, u otros recursos relevantes.
- Extracción de Datos mediante Scraping:
- Con requests y beautifulsoup4, se realiza scraping del HTML de las páginas sugeridas y se extrae el contenido de los artículos.
- La información se envía de nuevo al modelo LLM para obtener un resumen o descripción del contenido.
- Almacenamiento: Los datos se guardan en archivos .txt para análisis posterior.
4. Identificación de Proveedores y Fabricantes
- Descripción: Se siguen pasos similares al punto anterior para obtener una lista de proveedores y fabricantes en el área de interés.
5. Descripción y Análisis de Tecnologías Competitivas
- Descripción: Se genera una lista de tecnologías competitivas, que se envía al LLM para obtener descripciones detalladas y enlaces relevantes.
6. Normativas y Certificaciones
- Descripción: El LLM proporciona enlaces y normativas (ISO, IEC, etc.) para el proyecto. Se guarda la información para su consulta en futuras etapas.
7. Generación del Informe Final
- Descripción: Se genera un informe consolidado en .docx y .pdf con toda la información recopilada, utilizando python-docx y pdfkit.
Mejoras en el Procesamiento del Lenguaje Natural:
Entrenar un modelo especializado para entender y analizar mejor términos técnicos específicos del área de investigación.
Realizar pruebas adicionales con otros modelos de LLM para identificar alternativas más precisas.
Visualización de Datos: Crear dashboards interactivos para visualizar la información recopilada, permitiendo análisis rápidos y eficientes de patentes, artículos, y tecnologías de competencia.